malloclab
- week 05 {swjungle} {malloc-lab}
- 카네기 멜론 대학의 malloc-lab 과제 {PDF}
- ChoiWheatley/swjungle-week05-malloc-lab {GH}
- 0015.1 CSAPP Third Edition Bryant, Randal E. O'Hallaron, David. 💻 / 9. Virtual Memory {CSAPP} / ⭐️ 9.9. Dynamic Memory Allocation 실습을 기반으로 한 과제.
README#
본 문서는 카네기 멜론 대학에서 출판한 CSAPP 교재의 malloc-lab 과제를 직접 체험해 보면서 알게된 것들을 기록하는 공간입니다. 실제로 쓰이는 malloc을 구현하는 것은 아니고, 가상의 힙 영역(과제 시스템이 생성한 20MB크기의 메모리 공간)에 mm_malloc, mm_free, mm_realloc 인터페이스를 구현하며 request throughput과 memory utilization을 모두 챙길 수 있는 방법에 대해서 연구합니다.
교재에서 당부한 것과 같이 본 프로젝트는 1워드의 길이(WSIZE)를 4byte로 두고 더블 워드의 길이(DSIZE)를 8byte로 둔 채로 진행합니다. 원래 x86-64 시스템에서의 WSIZE는 64bit = 8byte입니다.
Implicit Free List#
https://github.com/ChoiWheatley/swjungle-week05-malloc-lab/pull/1
여기에서 'Implicit'이란, 프로그래머 기준에서 묵시적으로 가용 블럭을 찾는다는 의미입니다. 따라서, mm_malloc이 요청이 들어오면 해당 사이즈(바이트) 만큼의 가용 공간이 남는지 찾아야 합니다. 이때 블럭 자체의 메타데이터(size, allocated)를 저장하기 위해 블럭 앞 1워드를 할애하게 되는데, 그 구간을 Header 라고 부릅니다.
coalesce
병합 기능을 구현하면 메모리 사용성이 높아집니다. 외부 파편화가 줄어들기 때문인데, 이를 구현하기 위해 인접 블럭(특히 이전 블럭)을 참조해야 합니다. 따라서 헤더와 동일한 정보를 가지고 있지만 블럭 끝에 1 워드를 차지하는 Footer 를 두어 현재 bp(block pointer)에 2 워드 뒤로 가면 바로 푸터를 참조할 수 있게 만들었습니다.
개선사항#
performance index
Perf index = 44 (util) + 21 (thru) = 66/100
유틸 점수는 만점이지만 throughput 점수가 낮습니다. mm_malloc을 호출할 때마다 first fit을 찾아 처음부터 순회하기 때문에 속도가 느린 겁니다. 이번엔 가용블럭을 연결리스트로 만들어 가용블럭 안에서만 순회하는 Explicit Free List 기법으로 성능을 올려보겠습니다.
Smart Realloc#
https://github.com/ChoiWheatley/swjungle-week05-malloc-lab/pull/2
realloc 코드가 바로 옆 공간이 충분한데도 항상 malloc을 호출하는 것이 눈에 띄어 최적화를 해봤습니다. 인자로 들어온 사이즈는 단순 payload의 바이트 크기이므로 adjust_size 함수를 사용하여 헤더,푸터,8의 배수로 만들었습니다.
여기가 버그의 원인인데, !next.alloc && new_size <= bp.size + next.size 조건을 잘못 걸었던 것이 문제였습니다. 별 생각없이 사이즈의 합보다 작기만 하면 되는거 아냐? 할 수 있겠는데, 항상 생각해야 하는, MINIMUM_BLOCK_SIZE를 만족하지 못하면 할당할 수 없습니다.
performance index
Perf index = 46 (util) + 25 (thru) = 71/10
Next Fit#
https://github.com/ChoiWheatley/swjungle-week05-malloc-lab/pull/4
cur의 위치를 전역변수 g_cur로 보존한 뒤에 find_fit 호출 시 처음부터 탐색하는 것이 아니라 g_cur의 위치부터 탐색을 시작합니다.
performance index
Perf index = 45 (util) + 40 (thru) = 85/100
Explicit Free List#
MINIMUM_BLOCK_SIZE 값을 증가시키는 대신, 포인터 두개를 더 두어 가용 블럭끼리 순회가 가능하도록 만든 연결리스트를 Explicit Free List라고 부릅니다. free block은 payload 자리에 있는 prev, next 필드를 가지며, 할당된 블럭은 굳이 필요없습니다. 따라서 header를 기준으로 메모리가 정렬이 되어있게 됩니다.
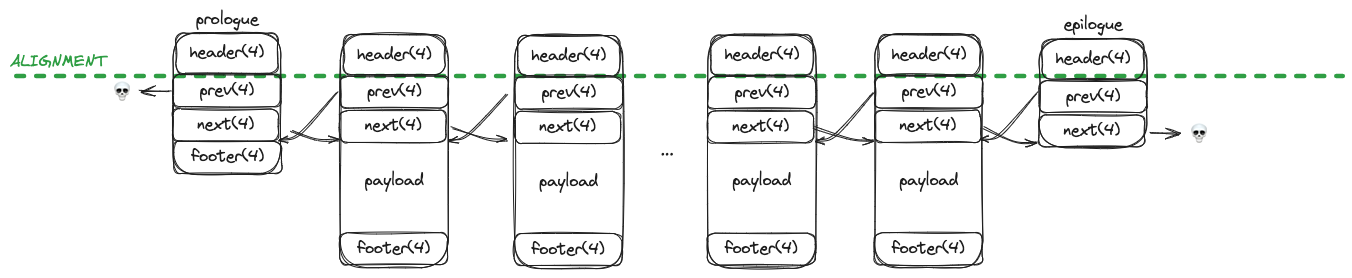
구현이 조금 빡세네요. 한 번 갈아엎고 다른 사람 코드 참고하면서 다시 작성했습니다.