Multi Level Feedback Queue {swjungle}{pintos}
README#
week07-10 {swjungle} {pintos} Project 1의 마지막 과제! NICE가 무엇인지, aging 기법을 활용했을 때 어떻게 starvation을 막을 수 있는지 여부를 알아낸 뒤 내가 어떤 것을 구현하여야 하는건지 목표를 파악한 뒤에 빠르게 구현까지 끝내보자.
Summary#
4.4 BSD Scheduler와 같은 multi-level-feedback-queue 스케줄러를 구현하여 평균 응답시간을 줄여라.
pintos 명령줄에 -mlfqs 옵션을 넣으면 threads/thread.h에 선언된 thread_mlfqs 전역변수가 TRUE로 수정된다. 이 경우 thread_create를 할 때 지정한 인자 중 우선순위 값을 무시한다. 더 이상 명시적으로 우선순위 지정이 불가하며, thread_set_priority, thread_get_priority는 스케줄러가 부여한 우선순위를 리턴하여야 한다. 아니, setter도?
mlfqs는 우선순위 기부를 하지 않기 때문에 우선순위 기부를 제외한 코드를 따로 호출하도록 만들어야 한다.
4.4BSD Scheduler#
범용목적 스케줄러는 존재한다! IO 작업이 많은 스레드는 응답시간이 빨라야 하지만 CPU time은 적게 먹는다는 특징이 있다. 컴퓨트 자원을 많이 요하는 스레드는 응답시간보다는 CPU time을 더 많이 먹는다. 대부분의 스레드는 응답시간, CPU time 요구량이 시간에 따라 변화한다. 범용목적 스케줄러는 이 모두를 만족시키기 위해 존재한다.
우리는 [McKusick] 방식의 스케줄러를 도입할건데, 자세한 내용은 Appendix에 있으니 참고바란다. 어쨌든 이 mlfqs는 말 그대로 여러 큐를 관리하며 그 중에서 가장 높은 우선순위를 가진 비어있지 않은 큐에 들어있는 스레드를 먼저 실행한다. 스케줄러가 큐 하나를 선택했다면 그 안에 있는 스레드들을 Round Robin 순서로 실행하게 된다.
Multiple facets of the scheduler require data to be updated after a certain number of timer ticks. In every case, these updates should occur before any ordinary kernel thread has a chance to run, so that there is no chance that a kernel thread could see a newly increased
timer_ticks()value but old scheduler data values.
스케줄러의 여러 측면에서는 특정 수의 타이머 틱 후에 데이터를 업데이트해야 합니다. 모든 경우에 이러한 업데이트는 일반 커널 스레드가 실행되기 전에 이루어져야 커널 스레드가 새로 증가된 timer_ticks() 값을 볼 수 있지만 이전 스케줄러 데이터 값을 볼 수 있는 가능성이 없습니다.
...?
Niceness#
Nice는 직역하자면 "친절한"이란 뜻이다. Nice 값이 높은 스레드는 다른 스레드에게 자신의 CPU 자원을 "친절하게" 퍼다준다. Nice의 값은 -20부터 20까지의 값을 가지며, 음수일 경우 반대로 다른 스레드의 CPU 시간을 빼앗는다. 스케줄러는 Nice 값에 기반한 공식을 사용하여 여러 스레드들의 우선순위를 동적으로 매겨 전체적인 response time을 줄이는 데 힘쓴다.
구현하여야 하는 코드는 threads/thread.c 파일 안에 있다.
thread_get_nicethread_set_nice
Calculating Priority#
priority = PRI_MAX - (recent_cpu / 4) - (nice * 2)
recent_cpu는 해당 스레드가 점유한 시간을 의미한다. 따라서 한 스레드가 오랜 시간 CPU를 점유할수록 우선순위는 떨어지게 된다. nice 값이 높으면 재선점될 일이 자주 찾아오지 않을 것이다. priority 값은 매 4 틱마다 계산을 수행하게 된다.
Calculating recent_cpu#
스레드가 지금까지 잡아먹은 시간을 리턴한다. 단순히 선형적으로 증가하는 것이 아니라 decay를 고려하여 점점 증가속도가 감소하도록 만들었다.
recent_cpu = (2 * load_avg)/(2 * load_avg + 1) * recent_cpu + nice
load_avg는 대기하는 스레드의 개수의 평균을 의미한다.
exponentially weighted moving average란 뭐야?
gpt의 답변:
지수 가중 이동 평균(Exponentially Weighted Moving Average, EWMA)는 시계열 데이터의 평균을 계산하는 방법 중 하나로, 최근 데이터에 높은 가중치를 주는 방법입니다. 이것은 과거 데이터보다 최신 데이터에 더 큰 중요성을 부여하여 시계열 데이터의 추세와 패턴을 민감하게 파악할 수 있도록 도와줍니다.
EWMA는 데이터 포인트를 가중치로 곱한 다음 이를 지수적으로 평활화하여 평균을 계산합니다. 가장 최근 데이터 포인트에는 더 높은 가중치가 부여되고, 시간이 지남에 따라 가중치는 지수적으로 감소합니다. 이를 통해 EWMA는 시계열 데이터의 빠른 변화를 민감하게 반영하면서도 잡음과 불안정성을 줄이는 데 도움이 됩니다.
EWMA를 사용하는 주요 이유 중 하나는 이동 평균을 계산할 때 지연(lag)을 최소화하기 위해서입니다. 일반적인 이동 평균 방법은 데이터의 일부를 버려야 하며, 이로 인해 지연이 발생할 수 있습니다. 그러나 EWMA는 모든 데이터 포인트를 사용하므로 지연이 줄어듭니다.
EWMA의 수식은 다음과 같습니다:
여기서,
- \( EMA_t \)는 현재 시간 \( t \)에서의 지수 가중 이동 평균 값입니다.
- \( x_t \)는 현재 시간 \( t \)의 데이터 포인트입니다.
- \( EMA_{t-1} \)은 이전 시간 \( t-1 \)에서의 지수 가중 이동 평균 값입니다.
- \( \alpha \)는 평활화 상수(0과 1 사이의 값)로, 높은 값일수록 최신 데이터에 높은 가중치를 부여합니다.
이러한 방식으로 EWMA는 최근 데이터에 민감하게 반응하면서도 지연을 최소화하여 시계열 데이터의 추세를 추정하는 데 유용합니다. 예를 들어, 주식 시장에서 주가 데이터를 분석하거나 수요 예측 모델을 개발할 때 EWMA는 많이 사용되는 기법 중 하나입니다.
Calculating load_avg#
지수적으로 가중치가 쌓이는 형태의 평균 대기 스레드 수를 리턴한다.
load_avg = (59/60) * load_avg + (1/60) * ready_threads
Fixed-Point Real Arithmetic#
17.14 고정소수점 실수연산을 사용해야 한다. 여기에서 32비트 정수형을 기준으로 LSB부터 14개의 비트는 fractional bits, 즉 소수부를 의미하고 17개의 비트는 decimal points, 정수부를 의미한다. 나머지 1 비트는 당연하게도 부호비트.
Tests#
- mlfqs-load-1: 하나의 스레드를 45초동안 재운다(busy waiting). 그 뒤에
load_avg를 검사하는데, 0.5가 나오게 만들어주어야 한다. 그 다음으로 10초동안 재운다(block). 그 뒤에load_avg를 검사하는데, 0.5보다 작게 나오게 만들어야 주어야 한다. - mlfqs-load-60: 60개의 스레드를 시작하여 동시에 10초동안 sleep 한다. 그리고 60초동안 busy wait를 하고 다시 60초동안 sleep한다. 세 과정 모두 60개의 스레드가 동시에 참여한다. main 스레드는 매 2초마다 전체
load_avg를 검사하는데, 처음 60초 까지는 계속 증가하다가 그 이후부터 감소해야 한다. - mlfqs-load-avg
- 60개의 스레드를 시작하는데 i번째 스레드는
10 + i초를 잔 뒤에 60초동안 busy waiting을 한다. 그리고 main 시작을 기점으로 120초가 지난 시점까지 다시 sleep한다. main 스레드는 매 2초마다 전체load_avg를 검사한다. 예상결과를 파싱하여 그래프로 그려봤는데 다음과 같다. 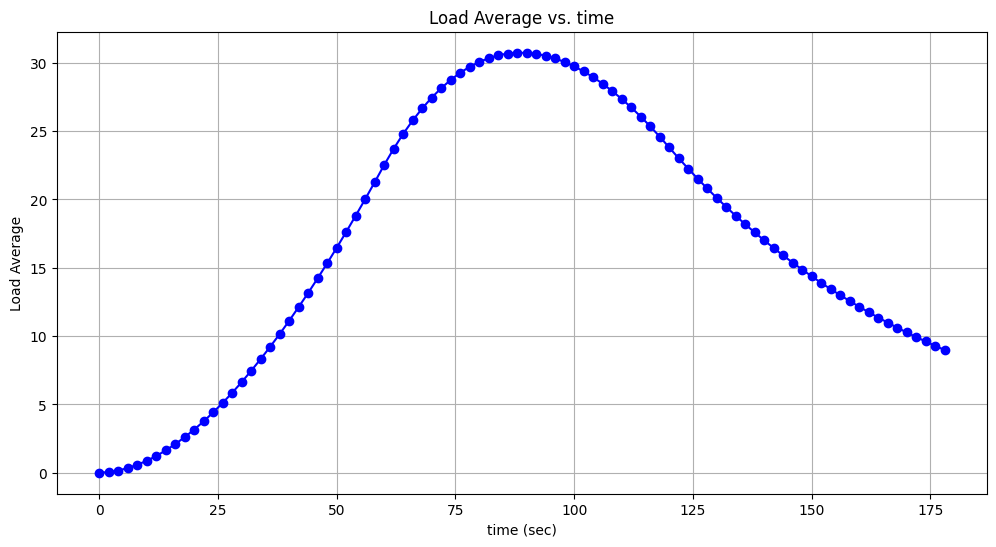
- 처음 70초 까지는 waiting thread의 수가 점점 늘어나 지수적으로
load_avg가 증가했지만 70초 이후부터는 깨어난 순서대로 스레드가 잠에 들기 때문에 변화량이 음수가 되어 서서히 줄어드는 모습을 볼 수 있다. 180초에 다가갈수록load_avg가 다시 0으로 수렴하지 않는 이유는 아무래도 평균을 기억하고 있어서 그런 것 같다.
- 60개의 스레드를 시작하는데 i번째 스레드는
- mlfqs-recent-1
recent_cpu가 올바르게 성장하는지 여부를 체크하는 테스트이다. 맨 처음 10초 sleep하여recent_cpu를 decay 시킨다. 그 뒤부터 180초동안 2초 간격으로recent_cpu,load_avg를 측정한다. 다음은 예제 결과를 그래프로 옮긴 결과이다.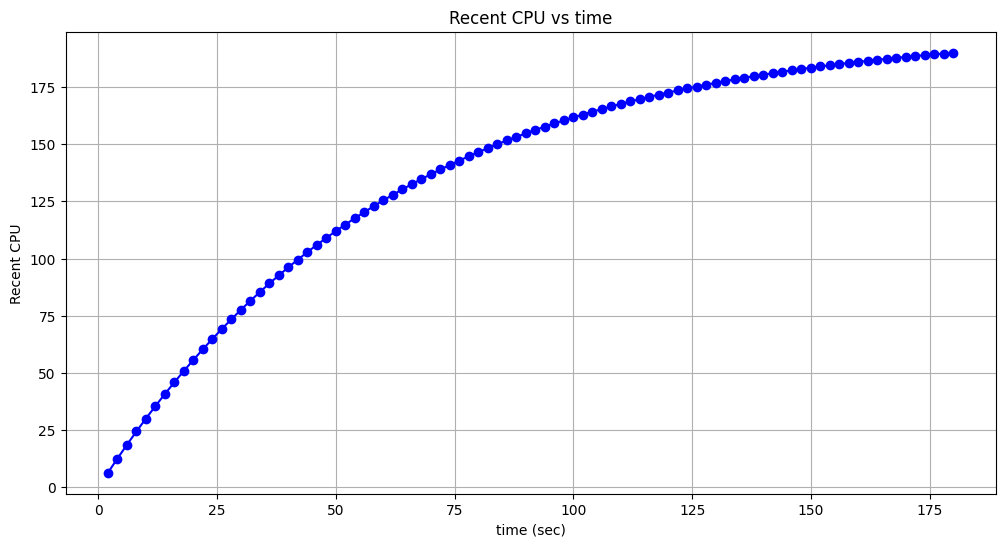
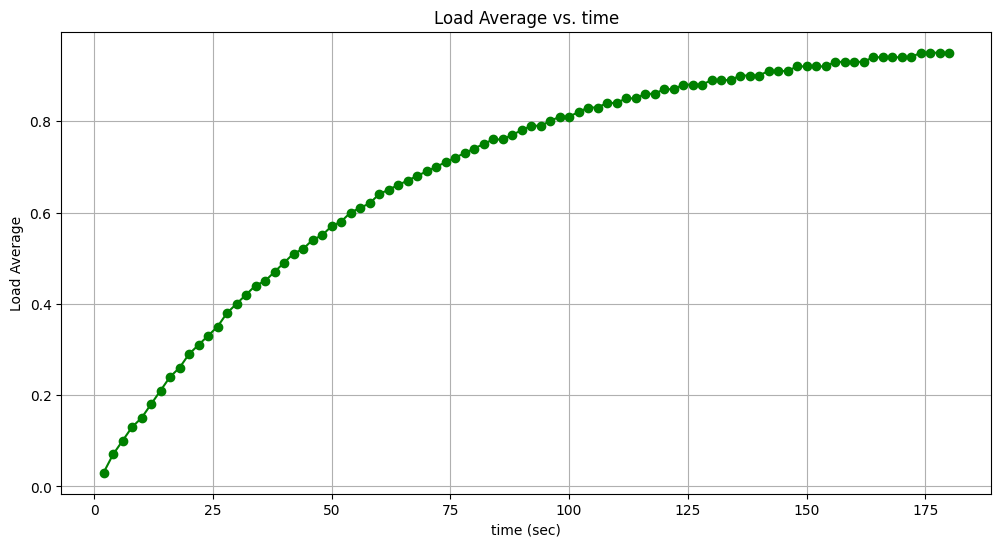
recent_cpu던,load_avg던 로그수준으로 증가하는 것을 알 수 있다. priority 계산 공식에 따르면recent_cpu가 증가할수록 priority가 낮아진다. 따라서 내가 연속적으로 CPU 자원을 점유하지 못하도록 만들어준다.
- fair/nice 시리즈
- nice 공식이 올바른지 여부를 판단한다. nice 값에 따라 스레드들이 점유한 tick의 개수를 비교한다. fair 시리즈는 n개의 스레드들이 공평하게 nice = 0으로 경쟁했을 때 tick의 숫자가 일정한지를 판단하며, nice 시리즈는 n개의 스레드들이
nice_step만큼 산술급수적으로 증가한다. - mlfqs-fair-2
- mlfqs-fair-20
- mlfqs-nice-2
- mlfqs-nice-10
- nice 공식이 올바른지 여부를 판단한다. nice 값에 따라 스레드들이 점유한 tick의 개수를 비교한다. fair 시리즈는 n개의 스레드들이 공평하게 nice = 0으로 경쟁했을 때 tick의 숫자가 일정한지를 판단하며, nice 시리즈는 n개의 스레드들이
- block
Implementation#
mlfqs-recent-1#
recent_cpu값을 1씩 증가시키는 코드 작성- 모든 스레드들의 priority와
recent_cpu값을 업데이트 하는 코드 작성
현재는 ready queue에 들어가는 스레드들이 정렬이 되어 들어간다. thread_mlfqs가 참일 경우, 정렬을 해서는 안되고 언제나 push back, pop front 해야한다.
매 틱마다 호출되는 timer_interrupt 안에서 Running thread의 recent_cpu를 1씩 증가시킨다. 매초 (100틱)마다 모든 스레드(running, waiting, blocking)들의 recent_cpu를 위에서 설명한 공식으로 갱신한다.
⟶ 아니, 그런데 어떻게 모든 스레드를 전부 순회하지? ready list는 그렇다고 쳐도, blocking 상태인 스레드는 lock acquire, sema down, sleep 다양한 조건에서 각자의 위치에서 blocking 상태에 있을건데 얘네들을 어떻게 찾지?
- 모든 스레드를 관리하는
g_thread_pool을 둬서d_elem으로 연결지어주면 된다.