INDEX#
- TLDR
- Onedrive 2021_1 Database1 수업을 기반으로 정리.
- 목표
- RDBMS의 기본을 이해합니다. (테이블, 외래키, 정규화)
- RDBMS가 제공하는 연산을 이해합니다.
- 트랜잭션에 대하여 이해합니다.
- 데이터 모델링을 이해합니다. (개념-논리-물리)
- ER Diagram을 그려봅시다.
- 테이블을 최적화하는 1,2,3정규화에 대하여 알아봅니다.
- keywords
- 테이블 Table
- 모델링 Modeling
- 외래키 Foreign Key
- 정규화 Normalization
- 조인 Join
- 인덱스 Indexing
- 트랜잭션 Transactions
RDBMS의 기본#
Relational Data Base Management System의 약자. 우리가 가장 익히 알고 있는 RDBMS에는 정형 데이터 처리 도구인 SQL family가 있다.
- 필드란
- 데이터의 속성 (성별, 키, 나이, 머리카락의 색상 등)을 정의하는 데이터.
- OOP에서의 필드는 멤버변수 혹은 프로퍼티라고도 불리운다.
- 칼럼(column)이란
- 특정한 타입에 의한 데이터 값들의 집합을 의미.
- 레코드(row)란
- 데이터를 정의하기 위한 여러개의 필드를 저장하고 있다. 레코드의 데이터를 접근하거나 수정하기 위해선 필드이름을 통해야 한다.
- 테이블이란
- 동일한 구조로 이루어진 튜플(레코드)의 집합
- DB란
- 여러 테이블을 묶어 관리하는 개념
- DBMS란
- 여러 DB를 관리하는 시스템
- RDBMS란
- 각 테이블 간의 관계는 외래키(Foreign Key)라는 공통칼럼을 가진다. 쉽게 말해 번지수임.
- 테이블간의 관계를 정의할 수 있기에 DBMS에 Relational을 붙여 RDBMS이다.
- DBMS 내의 자료검색에 최적화된 연산을 지원한다. (물론 CRUD는 제공)
- 테이블 기반으로 데이터를 저장하는 시스템.
- 테이블 > 칼럼 > 레코드
- 스키마 (Schema)
- 테이블 구조, 테이블 간의 관계를 정의. 이 외의 형식의 값은 허용되지 않는다.
- 스키마는 테이블을 만드는 블루프린트임.
- 모델링 (Modeling)
- 요구사항에서 DB 스키마를 만드는 작업
- 개념 -> 논리 -> 물리 모델링 순으로 이루어짐.
- 정규화 (Normalize)
- DB 스키마는 고정되어있지 않고 계속 변경된다. 따라서 스키마 설계를 재구성할 수 있는데, 중복 데이터를 삭제하는 방향으로 재구성하는 행위를 정규화라고 부른다.
- 또한, Create Update Delete 시에 발생할수 있는 이상현상을 제거할 수 있다.
- 정규화의 대표적인 예로 1,2,3,BCNF을 들 수 있다.
- 정규화를 하며 보통 테이블이 작은 테이블로 분할된다.
- 검색
- 일반적인 DBMS는 Create, Update, Delete보다 Retreive를 더 빠르게 만드는 것이 주요한 목표.
- 인덱스라는 개념을 사용해 빠른 검색이 용이. 기본적 인덱스 자료구조는 B+Tree
- 인덱스 파일만 별도로 구성하고 데이터 파일은 참조 형태로 관리. 인덱스는 CUD가 일어나면 재구성이 된다.
- 단점:
- 연속적인 검색(range search)에 느리다. => 연결 리스트를 사용하여 보완한다.
- 데이터의 추가 패턴에 따라 트리의 모양이 기울어질 수 있다. (skew)
Key#
- 테이블의 레코드를 검색할 때 하나의 레코드를 구별(식별)할 수 있도록 하는 기준. 유일성 (Unique) 기준을 만족해야 한다.
- 복합키(Composite Key): 하나의 칼럼이나 여러 칼럼을 묶어서 사용가능 (주민번호 + 학번 + 사번)
- 후보키(Candidate Key): 하나의 테이블에 Key가 될 수 있는 칼럼 (유일성 만족하기만 하면 다 후보키임)
- 대체키(Alternate Key): 후보키 중 기본키를 제외한 나머지 키
- 기본키(Primary Key): 후보키 중 선택된 키. PK가 없는 테이블도 가능.
- 외래키(Foreign Key): 다른 테이블(Relation)에서 PK로 사용되는 칼럼이 현재 테이블에서 사용되고 있을 때 ==> 테이블 간에 의도적인 중복을 허용하여 테이블을 합치는 연산인 조인 시 유용하게 써먹을 수 있다.
- ![[Drawing 2023-06-14 13.36.57.excalidraw|100%]]
- 식별관계(Identifying Relationship): 내 테이블의 FK가 PK인 경우
- 비식별관계(Non-identifying Relationship): 내 테이블의 FK가 일반 칼럼인 경우
- 참조 무결성 제약조건(Referential Integrity)
- 외래키로 연관 테이블을 검색하면 데이터가 반드시 존재하여야 함.
- 삽입, 삭제에 순서가 있어야 한다. 이 순서를 어기면 에러가 발생한다.
- 원본 레코드를 삭제하기 위해선 이 테이블을 참조하는 다른 테이블의 레코드를 먼저 삭제해야 한다.
- 반대로 외래키를 가지는 테이블이 레코드를 추가하고 싶다면 원본 레코드를 가진 테이블에 레코드를 먼저 추가하여야 한다.
조인#
- 여러 테이블을 합쳐 큰 테이블로 만드는 연산. 테이블이 나뉘어진 상태에서 원하는 데이터를 찾기 위해선 먼저 테이블을 합쳐야 한다. 왜냐하면 검색을 시작한 테이블에 내가 원하는 데이터가 존재할 거란 보장이 없기 때문이다.
- 조인은 테이블 단위 연산이다. 조인과정에서 테이블 간의 공통칼럼이 있어야 한다. 이를 표준 조인이라고 부른다. 이때 공통칼럼을 외래키라고 부른다.
RDBMS가 제공하는 연산#
DML#
- (Data Manipulation Language)
- selection
- 조건에 맞는 레코드 선택
SELECT * FROM employees WHERE 40 <= age < 50;
- projection
- 특정한 칼럼만 출력
SELECT name, age FROM employees;
- Join
- 2개 이상의 테이블을 합쳐 큰 테이블을 만든다.
- WHY? ==> 연관 데이터가 현재 테이블에 없기 때문에
- 드라이빙 테이블: (기준 테이블) (왼쪽 테이블) (부모 테이블) PK를 가지고 있는 테이블
- 드리븐 테이블: (오른쪽 테이블) (자식 테이블) FK를 가지고 있는 테이블
- (Inner) Join: 내부 조인: 두 테이블 간의 널 값을 허용하지 않음.
- Outer Join:
- Left Join: 드라이빙 테이블의 레코드가 누락되면 안된다.
- Right Join: 드리븐 테이블의 레코드가 누락되면 안된다.
- Full Join: 양쪽 모두 누락되면 안된다. (Inner Join?)
- Join 예시
- Table "employ"
- id/name/age/dept_id
- Table "dept"
- id/name
SELECT * FROM employ JOIN dept ON employ.dept_id = dept.id;- Joined Table "employ-dept"
- emp_id/emp_name/emp_age/emp_dept_id/dept_id/dept_name
- Table "employ"
- 비표준 조인 (Null에 대한 조건 완화)
- Cartesian Product (Cross Join): 두 테이블의 모든 레코드를 한 번씩 연결해서 만든 N * N 크기의 테이블을 만들어낸다.
- Equi-Join (Theta Join): Cartesian Product 중 실제 있는 레코드만을 필터
- union(합집합)
- 두 selection을 합친다.
(SELECT * FROM employees WHERE 35 <= age < 45) UNION (SELECT * FROM employees WHERE 30 <= age <= 40)
- Aggregation 집계함수 | wiki.org
SELECT * FROM employees GROUP BY dept_id;- group by 연산 수행 시 그룹별 통계값 (count, avg, min, max)을 확인할 때 주로 사용.
SELECT AVG(salary) as average_sal FROM employees GROUP BY dept_id;HAVING을 뒤에 넣어 필터를 걸 때 사용할 수 있다.
DDL#
- Data Definition Language
- create database
- drop database
- create table
- drop table
- truncate table
- alter table
- 제약조건
- NULL / NOT NULL
- UNIQUE
- PK
- FK
- CHECK
- DEFAULT
DCL#
- (Data Control Language) | gtg.org
- 루트를 제외한 유저들에게 권한부여하는 명령어 모음
- 사용자 생성
CREATE USER 'user1'@'localhost' IDENTIFIED BY 'test';
- 사용자 삭제
DROP USER 'user1'@'localhost';
- 권한 부여
GRANT ALL PRIVILEGES ON *.* TO 'user1'@'localhost';GRANT ALL PRIVILEGES ON database1.table1 TO 'user1'@'localhost';GRANT SELECT, INSERT, UPDATE ON database1.table1 TO 'user1'@'localhost';
- 권한 반영
FLUSH PRIVILEGES;
- 권한 확인
SHOW GRANTS FOR 'user1'@'localhost';
- 권한 삭제
REVOKE ALL ON database1.table1 FROM 'user1'@'localhost';
트랜잭션#
- RDBMS의 간판기능
- 트랜잭션의 모든 제약조건 (ACID)를 만족
- Atomicity: 원자성
- 커밋/롤백 보장 (All or Nothing)
- Consistency: 일관성
- Isolation: 격리성
- Durability: 내구성
- Atomicity: 원자성
- 트랜잭션의 모든 제약조건 (ACID)를 만족
- Lock
- 여러개의 트랜잭션(스레드)가 공유자원(DB/Table/Records)에 동시에 접근(CRUD)을 시도할 때 Lock을 통해 DB의 일관성을 보장함.
- Lock을 걸면 직관적으로 알 수 있듯이 오직 하나의 스레드만이 해당 자원에 대한 독점적인 접근권한을 갖는다.
- 다양한 종류의 Lock
- Global Lock: 명령 단위의 Lock, 즉, 어느누가 명령어를 제출하면 해당 연산을 마칠 때까지 다른 스레드 실행불가.
- Table Lock: 특정 트랜잭션이 독점적으로 테이블을 점유
- Record Lock: 특정 트랜잭션이 독점적으로 레코드를 점유.
데이터 모델링#
- 정의
- 현실 세계를 추상화, 단순화, 명확화 하기 위해 일정한 표기법에 의해 표현하는 기술
- 개념 모델링
- 현실 세계의 데이터를 추상화하여 개념 세계의 데이터로 표현하는 과정
- 모델링 결과가 E-R Diagram으로 표현된다.
- 핵심 엔티티 도출, EA(Enterprise Architecture, 전사적 아키텍처) 수립 시 활용.
- 논리 모델링
- 개념 세계의 개체 타입을 DBMS가 지원하는 논리적 모델로 변환하는 과정
- E-R Diagram을 구체화하여 관계 스키마(테이블, 외래키)를 만드는 과정.
- 정규화 (Normalization)
- 논리 모델의 일관성 확보, 중복 제거
- 물리 모델링
- 데이터가 저장될 수 있도록 논리 데이터 모델을 물리적 데이터 구조로 변환하는 과정
- 테이블 스키마 / 인덱스를 정의
- Entity Relationship Modeling
- Entity
- 엔티티는 고유하게 식별할 수 있는 독립적으로 존재할 수 있는 개체이다. 명사로 나타낸다. 엔티티는 현실세계의 물리적인 사물을 지칭할 수도 있지만 (집, 자동차, etc.) 논리적인 이벤트를 다룰 수도 있다. (거래, 서비스, etc.)
- 강한 엔티티 (Strong Entity)
- 홀로 존재 가능한 엔티티. (eg, 직원, 학생, 교수)
- PK를 가지는 충분한 속성을 가지고 있어야 한다.
- 약한 엔티티 (Weak Entity)
- 단독으로 존재할 수 없는 엔티티. (eg, 부서, 분반, 강의)
- PK를 가지기에는 부족한 속성을 가진다. 따라서 FK를 통해 강한 엔티티에 의존한다.
- Relationship
- 관계는 엔티티가 서로 어떻게 연관되어 있는지를 정의한다. 동사 형태로 나타나며, "학생이 수강하는 강의목록", "회사가 소유하는 컴퓨터" 등을 예로 들 수 있다.
- ER Diagram
- 엔티티-관계 그래프는 엔티티 집합과 관계 집합을 표현하기 위해 존재한다. 예를 들어 다이어그램에서 'song'이라는 이름의 엔티티는 곧 엔티티 집합을 의미하며, 'performs'라는 이름의 관계는 곧 관계 집합을 의미한다. 어떤 다이어그램에서는 이 집합의 수를 규정할 수 있는데, 이것을 Cardinality라고 부른다.
- Attributes
- 이름 그대로 속성인데, 속성은 엔티티, 관계 둘 다에게 붙을 수 있다. DB언어로 필드와 동등하다.
- 테이블을 Entity(1차)와 Relation(2차)으로 구분하는 작업.
- 학생 + 교수 테이블 ==> Entity 테이블 (1차)
- 강의 + 수강 테이블 ==> Relation 테이블 (2차)
- Peter Chen 표기법
- Entity = 직사각형
- Relationship = 마름모
- Attribute = 타원
- IE (Information Engineering) 표기법 (까마귀 발 표기법) | wiki.org | blog
- Entity 타입에 상관없이 직사각형으로 표현. Attribute는 Entity 하위에 포함되는 식.
- Relationship은 여러 모양의 선으로 표현할 수도 있다. Cardinality 제약조건에 따라 선의 모양이 다르다.
- 이 표기법은 Relationship에 Attribute를 명시할 수 없다. 따라서 관계 자체를 엔티티로 승격하여 사용하는 것을 원칙으로 삼는다. 따라서 동사의 이름을 가진 엔티티가 된다. 주로 과거 내역을 추적하고자 할 때 사용되는 기법이다.
Cardinality (대응수)#
- 1:1

- 하나의 개체가 하나의 개체에 대응
- 단일 테이블 내 칼럼 추가
- 1:N
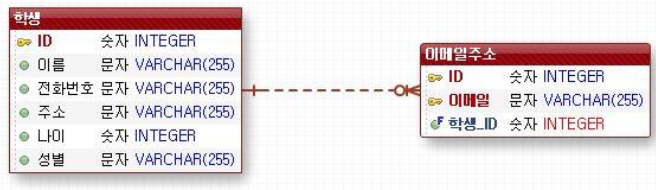
- 하나의 개체가 0..* 개의 개체에 대응
- 2개의 테이블 필요.
- N:1
- 0..* 개의 개체가 최대 1개의 개체에 대응
- 2개의 테이블 필요.
- M:N

- 0.. 개의 개체가 0.. 개의 개체에 대응
- 3개의 테이블 필요.
- 기본적으로 모든 관계는 M:N (다대다) 관계임.
- Entity -- Relationship -- Entity 이렇게 총 3개의 테이블이 필요함. 아래의 예제는 학생과 교수 사이에 다대다 관계를 강의라는 테이블로 정의한 것을 보여준다.

- M:N -> 1:N 또는 N:1 -> 1:1의 순서로 축소하면서 테이블의 개수가 줄어든다.
- 1:1, 1:N/N:1로 축소가 가능한 경우, 중간 관계(강의)를 삭제한 뒤에
- 1:1인 경우, 엔티티 안에 속성을 직접 추가한다.
- 1:N/N:1인 경우, 외래키로 엔티티 간 직접 연결한다.
식별관계와 비식별 관계#
- 식별관계 (Identifying Relationship)
- 강한 엔티티와 약한 엔티티 사이의 관계.
- FK가 테이블의 PK 또는 복합키로 들어있는 경우
- 실선으로 연결.
- 비식별관계 (Non-Identifying Relationship)
- 강한 엔티티와 강한 에티티 사이의 관계.
- FK가 테이블의 일반 칼럼으로 들어가 있는 경우
- 점선으로 연결
정규화#
| blog |
- 데이터 중복을 방지하기 위해 사용하는 모델링 기법.
- 1정규형 (1NF)
- 칼럼값이 원자값을 가지지 않으면 레코드 분리

- 2정규형 (2NF)
- 키 칼럼과 나머지 일반 칼럼이 직접적인 연관관계(직접 종속)만 가지도록 테이블을 구성.
- 아래의 예시는 복합키(학생번호, 강좌이름)가 성적을 식별하지만 동시에 키의 부분집합인 강좌이름 칼럼이 강의실을 식별하는 상황이라 강의실 테이블을 따로 분리하여 2NF를 만족시킬 수 있다.
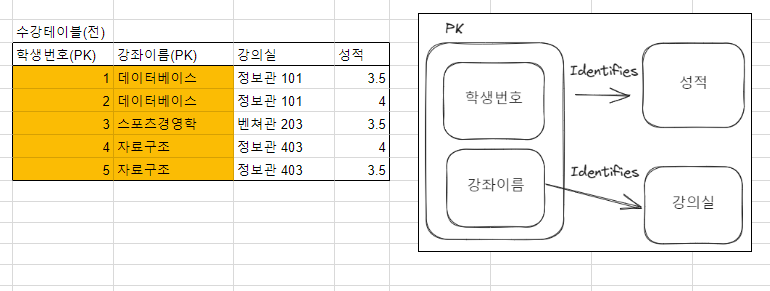
- 3정규형 (3NF)
- 일반 컬럼끼리 간접 연관관계 (간접 종속)을 가지고 있다면 테이블을 분리.
- 학생번호는 강좌이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다. 간접적으로 학생번호가 수강료를 결정하고 있으므로 테이블을 분리하여야 한다.
- BCNF 정규형 (Boyce-Codd Normal Form)
- 3정규형의 강화버전. 모든 결정자(식별자)가 간접 연관관계를 가지지 않도록 테이블을 분리.
N+1 Problem#
ORM의 문제점: 쿼리가 필요한 것보다 많이 요청된다.
지금 테이블에 연관 칼럼이 없을 경우 조인 연산을 수행한다. ORM은 user.orders...이런 식으로 자연스럽게 작성하게 되는데, 구현체 입장에서는 없는 칼럼 하나당 SELECT 쿼리를 날린다. 문제는 주문개수가 100개라면 단순히 연관 테이블의 멤버를 찾기 위해 100번의 추가적인 쿼리를 날려야 하게 된다.
사전에 필요한 테이블에 대한 내용까지 조인을 수행시켜놓는다. 앞으로의 ORM 요청에 대하여 조인한 테이블을 기준으로 찾으면 된다. (캐시잖아..!)