개요#
- 코드가 서비스의 전부가 아님. 인프라를 위한 JVM 튜닝, 데이터베이스 lock 조절 등의 저시기가 이루어짐
- Time To Market 시간을 줄이는 법 = 패키지에 의존한다. → 레거시의 동산에 온 것을 환영합니다.
- 레거시 시스템을 뒤엎고 새로 개발하는 것은 용기가 필요하다. 따라서 아키텍처링의 핵심은 현상황에 맞는 최선의 문제해결전략을 수립.
- VPC (Virtual Private Cloud)
monitoring#
서비스가 운영되고 있는 각종 상황들을 확인하는 행위의 전반을 의미. ex) 한문철 TV
[!note] Zero Trust 기반 이중화 서비스
믿을건 아무것도 없다. 서로가 서로를 감시하는 시스템이었으면 카카오 데이터센터 정보유실이 일어나지 않았을 것.
이상치 (전조)를 파악할 수 있는 여러가지 지표들이 있다.
- 호스트 지표
- CPU, 메모리, 디스크, 네트워크 IO
- 종합(Aggregated) 지표
- 캐시 적중률, DB 커넥션 개수
- 비즈니스 지표
- DAU(Daily Active User), MAU(Monthly Active User) 구매전환율
지표를 어떻게 확인할까?
- 리눅스 명령어
ps,top같은 명령어 → 서버에 직접 들어가는 부분이 단점이다. 만약 서버가 여러대라면? - 🤔 모든 서버들의 CPU 상태를 보고싶어. → CloudWatch와 같은 클라우드 서비스를 이용.
- 비즈니스 관점이 지표는 어디서 볼 수 있냐?
- Google Analytics
- Salesforce
- Datadog
- splunk
문제1#
쇼핑몰 서비스에서 평일 오후 2시에 특가 상품 판매를 시작했는데, 이용자들이 접속하지 못해 상품 구매를 하지 못하고 있다는 불만이 발생.
- 소비자들이 Time-out 페이지를 마주하고 있다.
- 관리자가 상황수습하기 위해 SSH를 시도해봤지만 접속이 불가하여 대응이 늦어지고 있다.
- 모니터링 지표를 보니 CPU 점유율, 서버애플리케이션 당 응답지연시간, Timeout 횟수 증가.
- 타임아웃 시간 자체를 늘려버림
- 반박: 사용자의 대기시간을 늘리는 것이 아닌가?
- 오토스케일링을 사용
- 반박: 오후2시가 아니면 낭비 아니야? 🤔 2시가 아닌 상황에서 어떻게 해야하지?
- 수동으로 종료한다.
- 자동으로 할 수 있지 않나? 아 이게 오토스케일링이구나
- 그룹크기조정정책 (Auto scaling policy)
- CPU usage, Connections
- 시작 템플릿
- 임계치를 넘겼을 때 실행시킬 스크립트 (인스턴스, 이미지, 보안그룹 등등)
- [?] 오토스케일링은 수평적 확장, 수직적 확장 모두 가능한가요?
- 반박: 오후2시가 아니면 낭비 아니야? 🤔 2시가 아닌 상황에서 어떻게 해야하지?
- CloudWatch - Lambda - Slack 알림
- Lambda: 스크립트를 실행시켜주는거. 슬랙 알림을 전송하는 봇.
머야, 답정너였잖아
서버가 외부 요청을 처리하기 위해선 충분한 자원 (CPU, Memory)이 필요하다. 요청 하나당 특정 규모의 CPU, Memory 사용량을 소모한다.
외부 요청이 증가하면 당연하게도 CPU와 Memory 소모량이 늘어난다. ==> 높은 CPU 점유율을 볼 수 있다. 자원부족은 곧 외부요청의 처리가 밀린다. ==> 응답지연시간이 늘어난다 ==> Timeout 횟수가 증가한다.
[!quote] 서버의 자원 규모를 늘려야 한다
해결: 수직적 확장과 수평적 확장#
- 수직적 확장 (Scale Up) = 서버 자체의 성능을 증대
- 서버의 Downtime이 필요함.
- Single Point Failure
- 수평적 확장 (Scale Out) = 서버 풀의 크기를 증대
- 설계를 바꾸어야 한다.
- 🤔 들어오는 요청을 어느 서버에 요청해야 하냐? ==> load balancer
- 요청들이 서버에 분산이 되도록 만들 수 있다.
- load balancer의 주소만 알려주면 그 뒤에 있는 여러 애플리케이션 서버가 배포되어 있는 내부 구현을 숨겨줄 수 있다.
- 서버 장애에 대한 내결함성을 확보할 수 있다.
- HOW? round robin: 서버가 1,2,3,4번이 있다고 하면 모든 요청을 순서대로 건내버림.
- 🤔죽은 서버에 대한 감시가 없으면 안되겠네?
- 🤔 세션이 저장되는 곳은 메모리 아닌가? A 서버에 저장된 쿠키 세션을 B 서버도 알게 하려면? → 무상태성이 확보되어야만 하다!!!
- NAS처럼 RAID 구성을 하면 가능할 것 같아요
- 반박: 파일은 기본적으로 잠금이 걸리게 된다.
- DB에 저장해도 되나요?
- 가능. 실제로 지원하는 기능.
- 프로세스들이 공유메모리를 참조하듯이 인스턴스들도 공유메모리를 참조할 수 있을 것 같아요
- 반박: 서버의 수가 증설되면 파이프의 수를 늘려야 하냐?
- 답정너: 무상태성을 확보하기 위해선 서버 애플리케이션이 사용하는 세션을 저장하는 서버를 하나 마련하여야 한다. Redis 메모리 기반 데이터베이스
- NAS처럼 RAID 구성을 하면 가능할 것 같아요
문제2#

- 버스트밸런스를 사용하면 초당 입출력 처리량 제한을 늘릴 수 있다.
- DB를 CloudSQL을 사용하면 확장이 가능하다. => 완전관리형 DB를 사용하자 RDS
- 반박: 완전관리형 DB에서 발생한 문제는? => 서버리스 서비스를 사용하면 되긴 함.
- 디스크 볼륨자체를 올려보자
- 쿼리 최적화 (필요한 쿼리만 실행)
- DB의 기존 연결 종료 & 최대 연결 수 증가
- 캐시서버 사용 Redis
- DB도 요청을 처리하기 위한 자원이 필요하다. DBMS들은 안정적인 작동을 위해 받아들일 수 있는 쿼리 요청 개수를 제한하는 설정이 있다. => DB Connection Limited 저시기가 발생할 수 있음.
- RDS Parameter Groups
- DB도 결국은 서버이기 때문에 서버의 물리적 규모를 확장하는 방식으로 문제해결이 가능.
- 캐시
- 단위: 클라이언트, DNS서버, 웹, 앱, 데이터베이스
- DBMS도 캐시를 가지고 있다. 그래서 유명상품들은 자주 접근되기 때문에 금방 나타났었던 것이다. (LRU cache) Hot Spot Problem
- Redis를 캐시서버로 활용할 수도 있다. => scale up
- 아무리 성능이 좋더라도 너무 비싸면 어쩌겠어 → 결국은 선택의 문제
- Read Replica를 생성하여 DB cluster를 확장 => scale out
- 주요 데이터베이스의 내용을 복제하여 읽기전용 DB를 만들어 관리
- Sharding 방식을 사용, 데이터를 나누어 저장하는 방법이 있다.
문제3#
https://aws.amazon.com/ko/blogs/korea/follow-up-to-the-november-22-event-in-aws-seoul-region/
- 부가가치에 대해서는 보상이 안된다는거. → 상품 시스템을 개선해보자.
- 리전
- 직역하면 '지역'. 물리적 데이터센터
- 리전을 다시 쪼개어 다양한 가용 영역(Availability Zone)으로 구성.
- 내결함성: 하나의 리전이 장애가 나더라도 서비스에 영향이 없도록 하는 것.
- DNS
- 인간이 읽을 수 있는 형태의 자원표기체계.
- 일부 DNS 서비스는 기본적인 매핑 외에도 다양한 요구사항을 수용할 수 있는 추가기능 제공. Route 53
해결방법에 대해서 논의해보자. - VPC Peering - VPC를 묶어서 도쿄나 북미쪽 리전을 연결. - 지리위치를 사용 - 반박: 가까운 지역에 맞추어 하는거라고 했는데, 서울에 있는 사람들은 서울리전, 도쿄에 있는 사람들은 도쿄리전에 접속하게 될 것이다. 둘 중 어느 한 리전이 장애가 발생했다고 가정하면, 지리위치라우팅 정책은 고정이기 때문에 결국 서비스 사용자가 장애가 발생한 리전으로 계속 라우팅 하게 될 것이다. - 지리근접이면 하나의 방법이 될 것 같다. - 분산데이터베이스 - 반박: 우리는 이미 MySQL 쓰고 있고, 새로운 DB를 도입하는 데에 비용이 든다 (시간) - 멀티클라우드 - 여러 공간에 있는 자원을 하나의 큰 서비스로 엮어주는 서비스.
복구 전략 - 우리가 어느 정도로 서비스를 띄워놓을 것인지. 얼마나 대비해놓을 것인지에 대한 수준을 정해놓을 수 있다. 안정성 원칙에 4가지 옵션이 있다. - RPO: Recovery Point Objective: 허용할 수 있는 데이터 손실양. - RTO: Recovery Time Objective: 장애 발생시 원상복구 하는데 소요되는 시간. 최대 허용 다운타임 - 몇 시간 안에 복구되면 ok - 수십분 안에 복구 - 몇분안에 복구 - 실시간에 가까움 - 백업 & 복원 - 전체 워크로드의 백업본만 백업 리전에 백업 - 파일럿 라이트 - 전체 워크로드 중 핵심적인 부분만 백업 리전에 백업 -> 복구를 위해서 바로 꺼내올 수 있어야 하는 (실행) - 웜 스탠바이 (warm standby) - 전체 워크로드를 백업 리전에 유지하기. 다만 전체 워크로드의 크기를 줄여야 함 - 액티브 액티브 - 전체 워크로드를 경량화 하지 않고 그대로 복제
문제는 데이터베이스... 데이터가 동기화가 되어야 할텐데..? - Read Replica의 경우는 원본을 복제하여 읽기전용으로 유지할 수 있었다. 하지만 서로 다른 VPC 안에 있는 DB를 Read Replica로 만드는 것은 불가능하다. - 하드웨어 저장소의 문제. SSD나 HDD가 물리적으로 리전 안에 붙어있기 때문에 안에서는 묶어줄 수 있는데, 외부 저장소를 같이 동기화 하는 것은 어떻게 해야 할까? - Cross Region Replication - AWS 내부망을 통해서 리전 간 replication을 지원.
두 번째 문제인 DNS 설정. - Route53의 Failover Routing Policy를 설정. 일본인들도 접속하는데 불만이 없다는 가정 하에 지리근접리전을 제공하는 것을 제외한다면,
복구행동계획 - 장애의 영향도를 확인. 어디에서 장애가 발생했는지, 어디까지 영향을 미치는지 - 리전 전체의 문제라면 Route53의 정책을 확인 - 백업리전의 RDS Read Replica를 승격시켜 Read/Write가 가능하도록 만든다.
문제3#


HINT: Data에 어떤 문제가 있을까요?
- 서비스 오류 문제는
- UUID를 사용하면 되는 문제 아닌가?
- 동시성의 문제와는 다른 것 같다.
- 올리브영의 문제가 그렇듯이 부하가 걸리면 인덱스가 깨진 저시기가 있다.
- Primary Key를 Auto increment하는 기능이 작동하지 않았던 것이 용의자
- 트랜잭션 2단계 locking을 사용.
- Queueing을 사용해볼까?
- 큐잉 전용 인터페이스를 만들어볼 수 있다.
- UUID를 사용하면 되는 문제 아닌가?
- 성능저하건은 쿼리에 대하여 Table Full Scan이 발생.
- 정규화?
- DB Sharding
- MySQL이 샤딩을 지원하지는 않다. 그리고 샤딩이라는 개념 자체는 서로 다른 노드에 서로 다른 데이터를 쪼개어 넣는거.
- View Table: 가상 테이블을 만들 수 있다. 필요로 하는 정보를 SELECT 하여 테이블을 만들 수 있다.
- PostgreSQL의 경우 View를 통해 만들어지는 데이터가 따로 빠져나가 캐시처럼 빠르게 접근할 수 있는 매커니즘을 제공하기는 함. 하지만
- MySQL의 경우 View 테이블처럼 말아놓는 수준이 아니라 쿼리를 말아놓는 거라고 볼 수 있기 때문에 제약이 존재.
답정너
- 대규모 시스템에 맞는 데이터 모델을 고안하는 것이 필요하고
- 확장 가능한 인프라 구성으로 이어져야 한다.
- 서비스 오류:
- 일단 Auto Increment사용되지 않았다는 문제에 대해서는 일단 Auto increment를 적용하면 된다. (...)
- 🤔 근데 Multi Primary 환경에서는? 우리가 백업리전에 Read Replica만 만들었던것과는 다르게 Primary 데이터베이스가 여럿일 경우 어떻게 설정해줘야 할건지?
- ID를 구할 때 1만큼 증가하지 않고 k만큼 증가하도록 설정.
- 단, Primary 인스턴스 개수가 변동일 경우 k를 그때그때 바꿔야 하므로 유연하지 못함. => 고유 ID 생성 메커니즘이 필요.
- Queuing이라는 방법도 고유한 ID를 보장할 수는 있지만 비동기로 처리되다보니까 시간이 약간 걸리는 케이스가 발생할 수 있음. => 좋지 못한 UX
- ID를 구할 때 1만큼 증가하지 않고 k만큼 증가하도록 설정.
- UUID가 나오네 이걸
- 전체 웹 서버 클러스터에 걸쳐 보편적이게
- UNIX
timestamp=time_low + time_mid + time_hi - Clock Sequence: UUID의 유일성을 보장하기 위한 무작위 컴포넌트. 랜덤값에있어서 16bit를 넣을 수도 있는거고.
- Node: 서버 인스턴스의 ID
- 1초당 만들어질 수 있는 고유 ID의 개수는 \(2^{16} \textasciitilde 2^{64}\)
- 성능저하:
- 기본적으로 테이블 데이터는 하나의 파일에 저장된다.
- 테이블 규모가 커지게 되었을 땐 파일의 크기가 커지고, 탐색시간이 증가하게 된다.
- 탐색시간을 줄이는 방법으로는 인덱싱과 파티셔닝/샤딩 기법을 사용할 수 있다.
- Index
- 모든 컬럼을 인덱싱 하기보다는 중요도가 높은 (PK) 컬럼을 기준으로 정렬을 한다.
- 하지만 데이터 쓰기에는 오버헤드가 발생하게 된다.
- Multi-Column Index: 여러 컬럼을 묶어 인덱싱 하는거.
- 모니터-고해상도모니터-MSI 까지를 통째로 묶어서 인덱싱을 하면 depth가 낮아지겠지?
- 파티셔닝/샤딩
- 데이터 분할저장. 덩어리 파일을 쪼개어 별개의 파일로 관리.
- 파티션 크기를 정하는 규칙:
- 모든 파티션의 데이터 양의 균형을 맞추는 것이 중요. 5월 데이터의 양 <<<<<< 6월 데이터의 양이라면?
프로젝트 아키텍처링 실전 설계#
SNS 서비스의 뉴스 피드 시스템 설계. 뉴스피드란, Home에 들어가면 보이는 게시글들을 뉴스피드라고 한다. 친구, 나와 친구인 사람, 팔로우중인 사람 (글, 사진, 영상, 링크)
요구사항#
- 플랫폼
- 모바일 & 웹 둘 다 지원
- 주요기능
- 뉴스 피드 페이지에 새로운 스토리를 올릴 수 있어야 하고, 친구들이 올리는 스토리를 볼 수도 있어야 한다.
- 뉴스피드의 노출순서
- 가중치는 없고 단순히 시간 흐름의 역순으로 설계.
- 한 명의 사용자는
- 최대 5000명의 친구를 가짐
- 아시아 권역만 한정지어서
- 트래픽 규모
- 매일 천만명
HINT - 어떤 데이터들이 필요한지, 어떤 기능이 어떤 데이터를 참고하는지, 데이터들을 각각 어디에 저장할지 - 문제의 복잡성을 줄이기 위해 피드 업로드 API와 읽기 API만 만든다.
Use Case
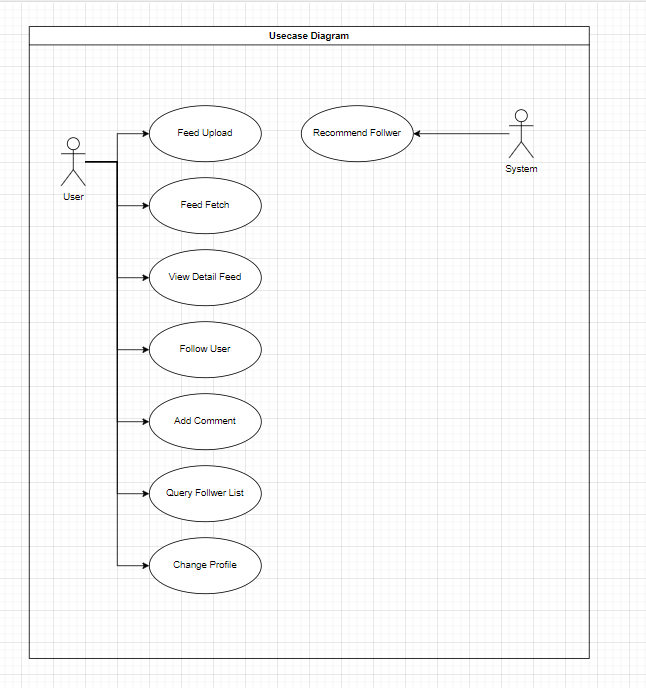
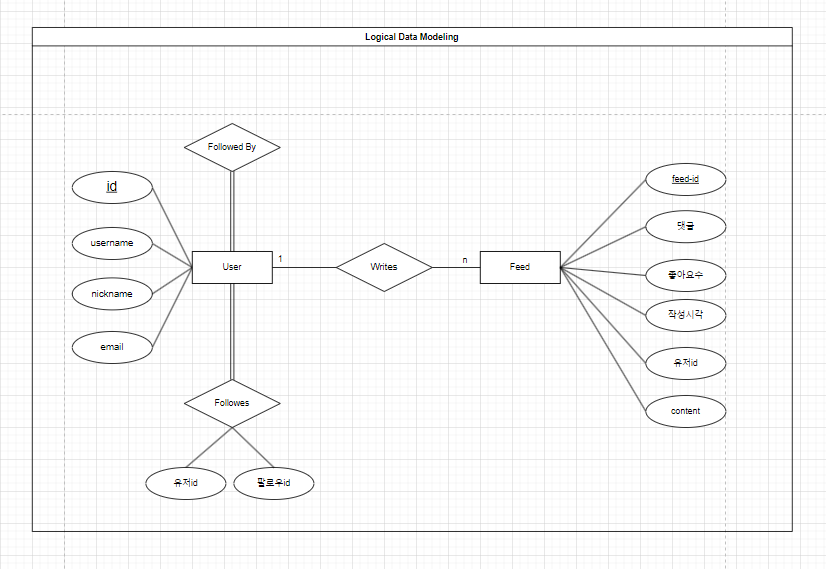
Logical Model
Component
- Multi AZ 설계를 해봤다. → 수평적 확장
- public subnet에는 EC2를, private subnet에는 보호하여야 할 DB를 넣고.
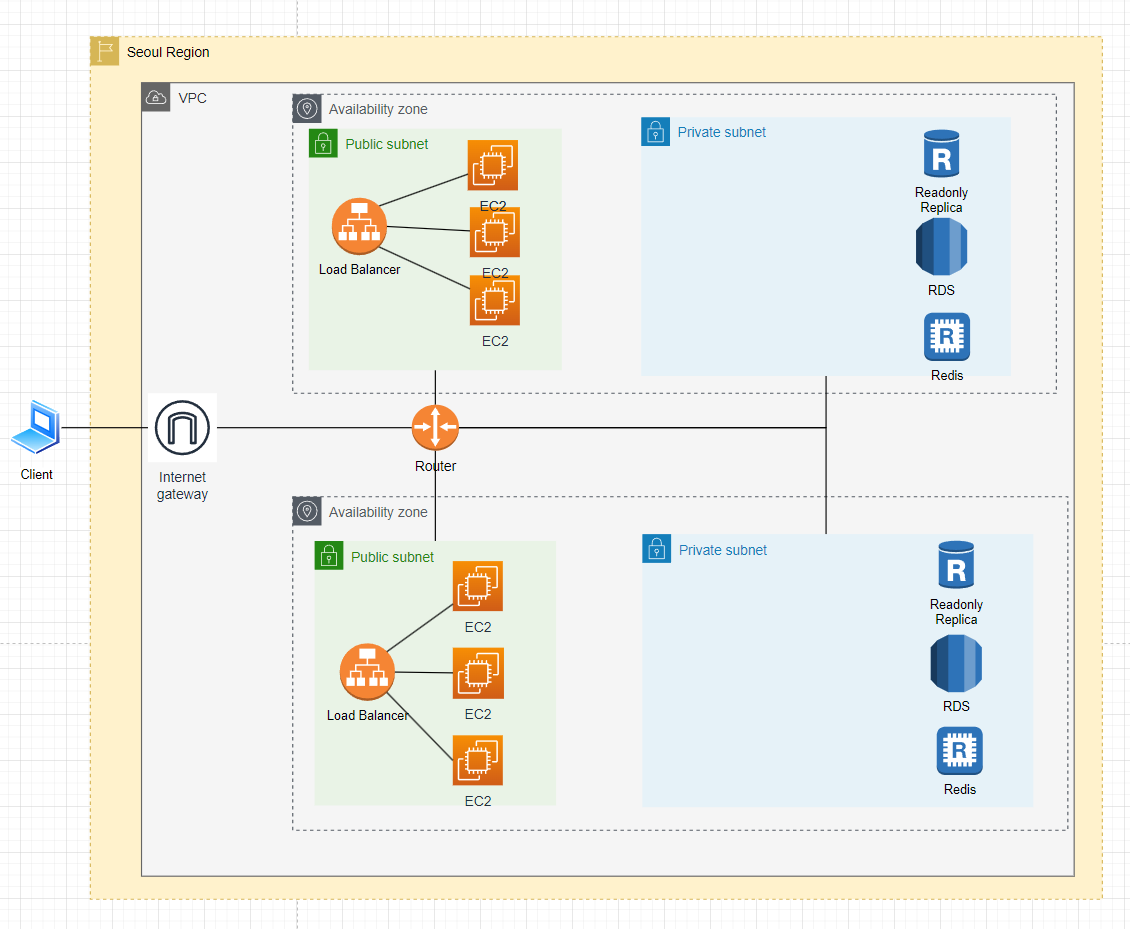
- Feedback: 별도의 로드밸런서를 사용하는 것처럼 보였으나 하나가 있었으면 좋겠다.
- 캐시로 둬야 할 데이터들
- 로그인 정보
- 개별 사용자의 뉴스피드: 사용자가 근시간 내에 확인할 만할 소식을 올려둠
- 뉴스 피드의 반응 (좋아요, 댓글 등)
- 메시지 큐: 포스팅 전송작업을 큐잉한다.