SW 정글 과제로 공부한 BeautifulSoup#
- 노션에 정리해놓은 파이썬 + DBMS 소스에 BeautifulSoup가 있다
- 아쉽게도 네이버 영화 PC 서비스 페이지가 종료되어 아래 코드는 제대로 동작하지 않는다.
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어 HTML을 받아오고,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(
'https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303', headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup라는 변수에 "파싱 용이해진 html" 이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출.
soup = BeautifulSoup(data.text, 'html.parser')
print(soup) # HTML을 받아온 것 확인
# select를 이용하여 tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
print(len(movies))
for movie in movies:
print(movie)
# 각 영화에서 영화제목이 적혀있는 a 태그를 select_one()으로 찾아본다.
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
print(a_tag)
# 그 중 내용이 있는 경우에만 텍스트를 프린트한다.
print("print ac, a_tag, point")
for movie in movies:
ac = movie.select_one('td.ac > img')
a_tag = movie.select_one('div.tit5 > a')
point = movie.select_one('td.point')
if (ac is not None and
a_tag is not None and
point is not None):
print(ac.attrs['alt'], a_tag.text, point.text)
오르미 크롤링 과제#
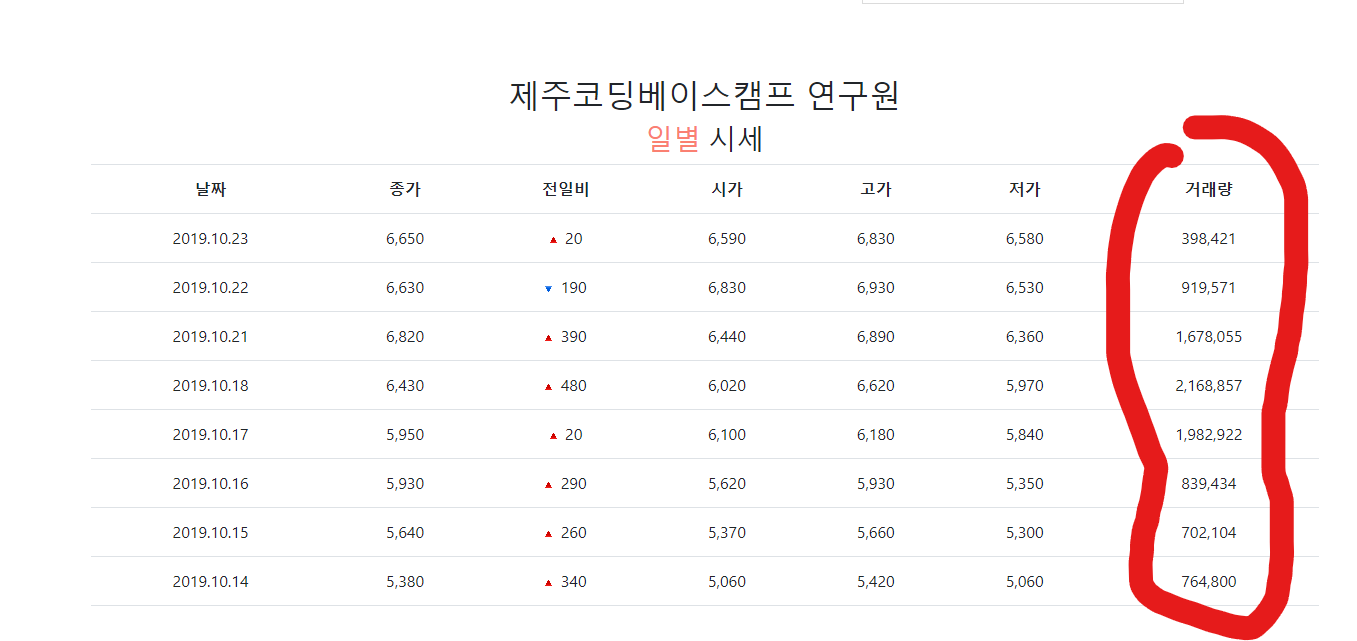
문제:
제주코딩베이스캠프 연구원에 2019.09.24 ~ 2019.10.23 까지 거래된 거래 총량을 구해주세요. 데이터 링크는 https://paullab.co.kr/stock.html 입니다.
요구사항 파악#
이제 진짜 일을 해보자. 문제 조건을 먼저 파악해보자.
- 크롤링 연습용 페이지에 html 소스를 요청하여
- 일별 시세 표를 파싱한 뒤에
- 주어진 구간의 날짜 (2019-09-24 ~ 2019-10-23)의 데이터를 쿼리하여
- 거래량 속성의 합을 구하여라
import requests
from bs4 import BeautifulSoup
from datetime import date
from_date = date.fromisoformat('2019-09-24')
to_date = date.fromisoformat('2019-10-23')
headers = {
'User-Agent': 'Chrome/113.0.5672.93'
}
# Get html content
data = requests.get('https://paullab.co.kr/stock.html', headers=headers)
# 검색이 용이한 상태로 만들어주는 파서 `BeautifulSoup`의 도움을 받자
soup = BeautifulSoup(data.text, 'html.parser')
# CSS select 구문을 사용하여 html 요소들을 분석할 수 있다.
researchers = soup.select('#제주코딩베이스캠프연구원 ~ .table > tbody > tr')
head = researchers[0].select('tr > [scope="col"]')
head = [h.text for h in head]
# print(head)
table = []
for row in researchers[1:]:
row = [r.text.strip().replace(',', '') for r in row.select('tr>td>span')]
data = dict()
for idx, value in enumerate(row):
key = head[idx]
match key:
case '날짜':
data[key] = date.fromisoformat(value.replace('.', '-'))
case _:
data[key] = int(value)
table.append(data)
print(f'''{from_date}와 {to_date} 사이의 거래량 속성의 합은 {
sum(map(lambda x: x['거래량'], table))
} 입니다.''')